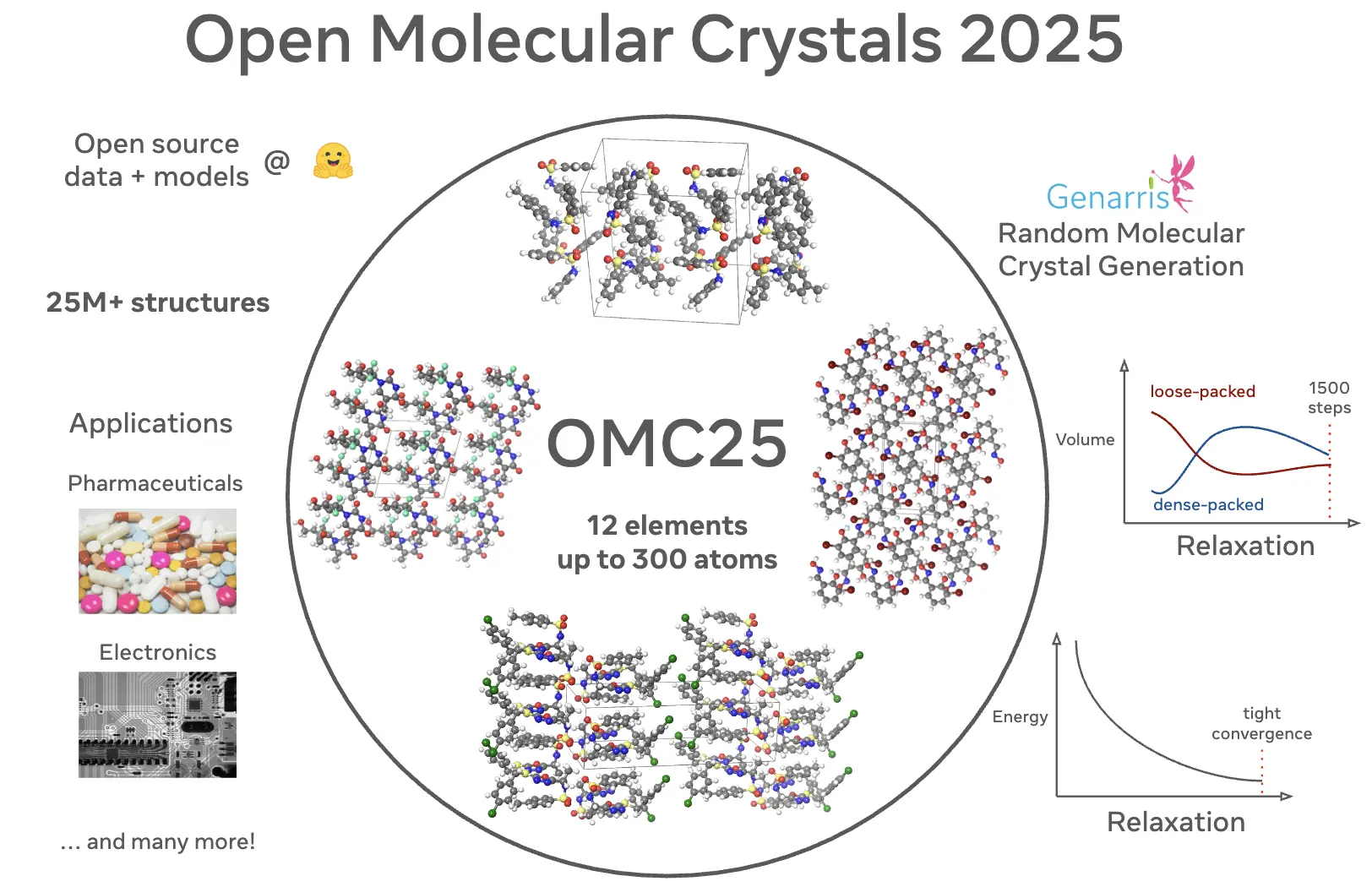
Open science
Datasets
Materials
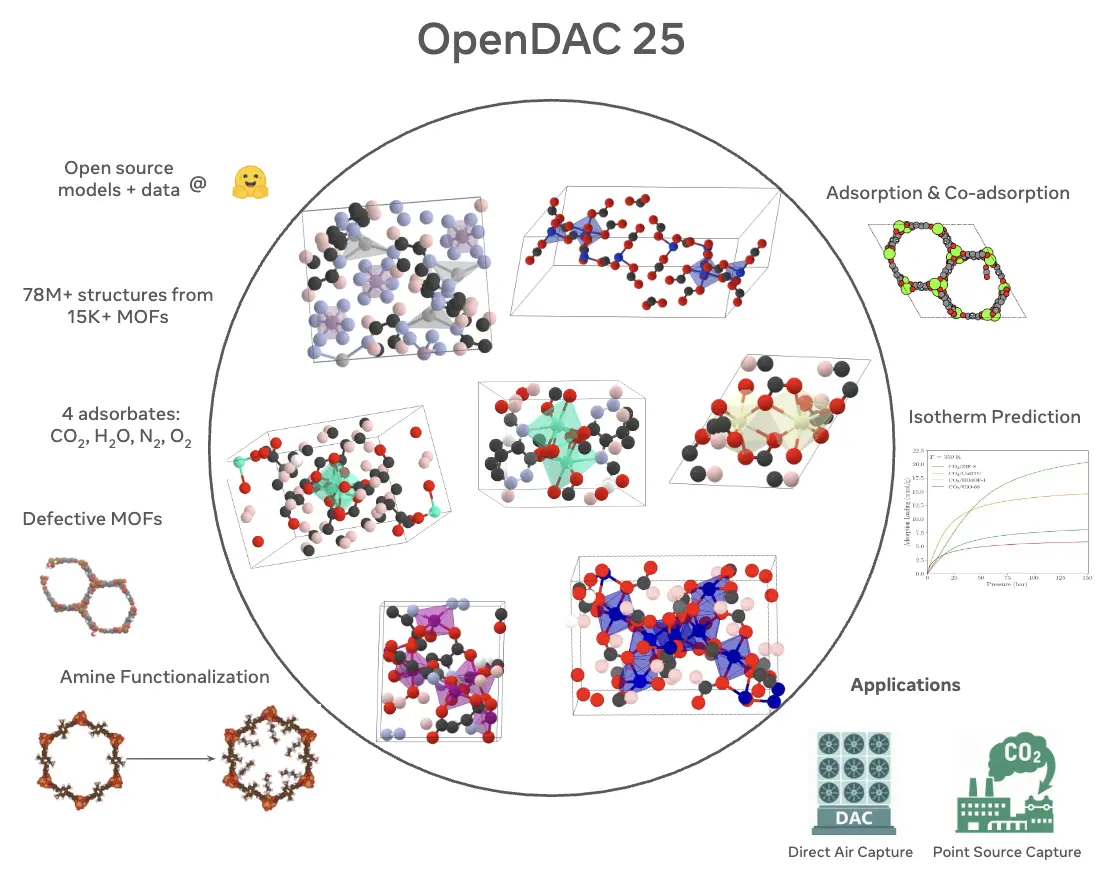
Open DAC 2023 & 2025
Datasets for sorbent discovery in Direct Air Capture. ODAC23 provides more than 38 million DFT calculations across more than 8,800 MOFs; ODAC25 expands to nearly 70 million DFT single-point calculations across 15,000 MOFs with four adsorbate species. Released with machine-learned interatomic potentials.